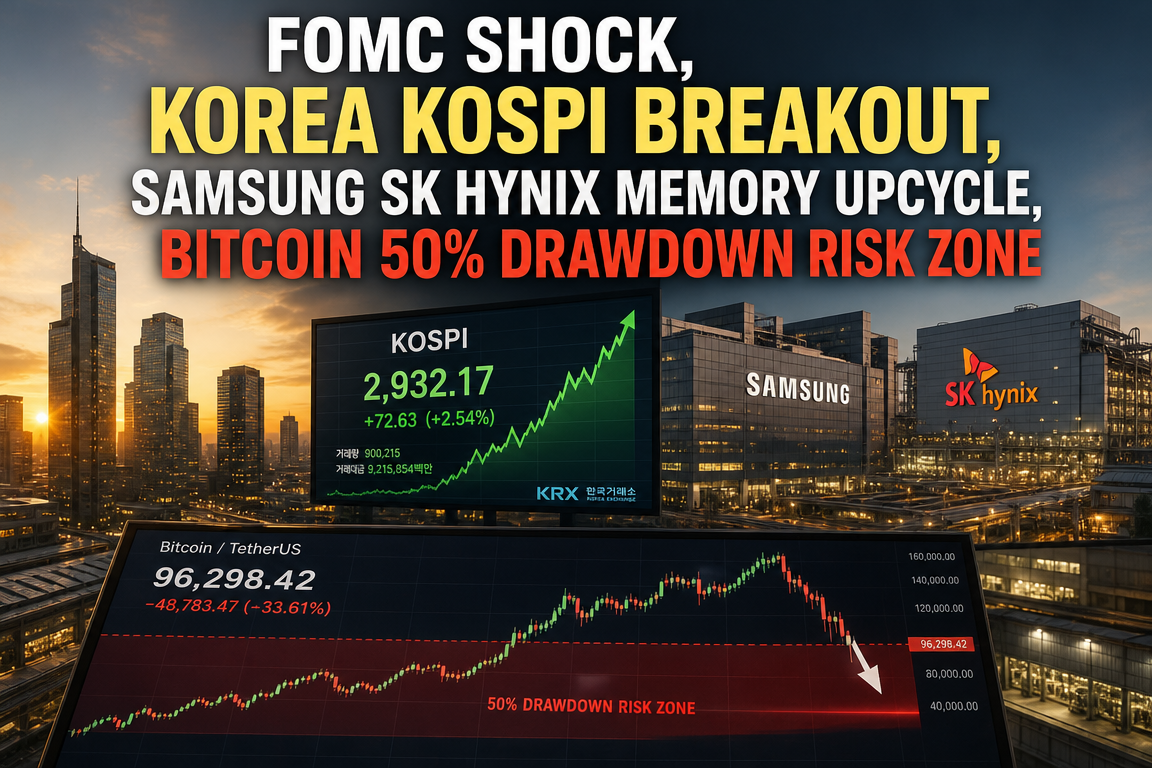
웨이모가 말하는 ‘자율주행의 끝’ 전략: 월드모델로 시나리오를 억대로 만들고, 드라이빙 에이전트를 끝까지 학습한다
오늘 글에서 꼭 챙겨야 할 3가지(시작부터 핵심)
1) 웨이모는 도로 실데이터만으로 끝내지 않고, 월드모델(world model)로 “상상 가능한 시나리오”를 대량 생성해서 학습을 확장한다는 방향이 핵심이에요.
2) 목표는 “현실에서 잘 달리는 수준”이 아니라, 생각할 수 있는 모든 시나리오에서 트레이닝을 완벽하게 만드는 것—그걸 자율주행의 ‘끝’으로 본다고 말합니다.
3) 그리고 학습 방식은 과거처럼 룰베이스만으로 가기보다, 강화학습 + 월드모델 기반 시뮬레이션을 중심으로 드라이빙 에이전트를 더 고도화하는 흐름이 강하게 드러나요.
오늘은 이 인터뷰 내용을 “뉴스형”으로 재구성해서, 웨이모의 학습 철학과 기술 포인트를 한 번에 정리해드릴게요.
뉴스 요약(한 줄 브리핑)
웨이모는 도로 주행에서 수집한 실데이터에 더해, 월드모델로 대규모 시뮬레이션 시나리오를 만들고 드라이빙 에이전트를 강화학습으로 끝까지 훈련하는 방식으로 자율주행의 한계를 밀어붙이고 있다고 밝혔습니다.
1) 웨이모의 핵심 학습 철학: “실데이터 + 월드모델 시나리오 무한 확장”
1-1. 실데이터만으로는 ‘리스크가 남는다’는 문제의식
인터뷰에서 강조된 건, 현실 주행으로 얻는 데이터가 엄청나게 중요하다는 점은 맞지만,
“현실에서 겪을 수 없는(또는 매우 드물게만 일어나는) 위험 상황”까지 커버하기엔 구조적으로 한계가 있다는 거예요.
1-2. 월드모델이 하는 일: 센서 데이터를 ‘생성’해서 학습 재료를 만든다
여기서 등장하는 게 월드모델인데요.
일반적으로 월드모델은 정의가 아직 모호할 수 있다고도 말하면서, 웨이모가 만든 월드모델은 특히
카메라·라이더 같은 센서 데이터를 생성해 주는 모델이라고 정리합니다.
즉, “세상이 어떻게 보이고(센서 입력), 어떻게 움직이는지”를 학습에 쓸 수 있도록 시뮬레이션 가능한 형태로 만드는 역할이 핵심이에요.
1-3. ‘시나리오 수’를 자율주행의 성능으로 연결한다
인터뷰에서 가장 강하게 꽂히는 대목이 이 부분입니다.
웨이모는 월드모델을 통해 정말 많은 시나리오를 만든 뒤,드라이빙 에이전트를 수만/수십만/수억 개 시나리오에서 트레이닝하는 방향을 이야기합니다.
그리고 결론은 명확해요.
“생각할 수 있는 모든 시나리오에서 트레이닝을 완벽하게 시키는 것”— 그게 자율주행의 끝이라고 본다는 거죠.
2) ‘열린 학습(월드모델) vs 닫힌 학습(고정 환경)’ 관점 정리
2-1. 오픈루프(고정된 환경) 학습의 한계
인터뷰에서 비교하는 틀은 대략 이렇습니다.
- 오픈루프 트레이닝: 특정 도시/맵 등 환경을 고정하고 에이전트를 훈련
- 예: 서울을 맵핑해 벽에 부딪히면 페널티, 신호를 어기면 리워드/페널티 부여 같은 방식
문제는, 이런 방식은 “많은 시나리오를 동시에” 만들기가 어렵다는 점이에요.
2-2. 클로즈루프(월드모델 기반)로 시나리오가 폭발한다
그래서 웨이모는 월드모델로 시나리오를 먼저 만들고,그걸로 드라이빙 에이전트를 대규모 강화학습에 태우는 구조로 가고 있다고 설명합니다.
이게 실무적으로 왜 중요하냐면,
희귀 상황(예측하기 어려운 상대 차량 동작, 상상하기 힘든 돌발 상황)을 자주, 반복적으로 학습시킬 수 있기 때문이에요.
3) 파운데이션 모델(또는 거대모델)이 자율주행에 들어오는 지점
3-1. “LLM은 추론(리즌닝) 쪽에서 강점”
인터뷰에서 말하는 프레임은 간단합니다.
LLM 같은 언어형 모델은 리즌닝에 많이 적용된다는 관점이에요.
3-2. VLA 흐름: 비전-언어-행동을 연결하는 방식
최근 트렌드로 언급된 게 VLA(비전-언어-액션) 관점이에요.
예를 들면,도로에 빨간 신호등이 보이면, 그 상황에 맞는 행동(정지 등)을 “해석+결정”하는 쪽으로 연결될 수 있다는 의미죠.
3-3. 룰베이스를 파운데이션 모델로 확장하려는 이유
핵심 이유는 “시뮬레이션/월드모델에서 드라이빙 에이전트를 트레이닝하기가 유리해진다”는 점입니다.
즉, 모델 기반 접근은
다양한 상황 대비를 더 잘 할 수 있고,
현실에서 구현이 어려운 시나리오까지 학습 재료로 끌어올 수 있다는 거예요.
4) 웨이모는 ‘R&D vs 프로덕트’ 중 어디에 더 무게를 두나
4-1. 과거엔 프로덕트 이미지가 강했지만, 최근은 R&D도 크게 늘렸다
인터뷰에 따르면 초기엔 프로덕트 중심 분위기가 있었다고 들었는데,최근에는 LM(거대모델)을 쓰기 시작하면서 R&D에도 많은 리소스를 투입하고 있다고 답합니다.
4-2. 분위기 요약: “미션 드리븐 + 사고의 비용이 크기 때문에 더 빡세다”
웨이모는 누구나 알고 있는 것처럼 자율주행은 결과의 리스크가 크잖아요.그래서
LM이 잘못되면 사고로 이어질 수 있다는 현실 때문에, 미션에 집중하는 문화가 강하다고 해요.
5) ‘학습/개발을 더 빠르게’ 만드는 인프라 관점(엔지니어 경험에서 나온 이야기)
5-1. 거대 모델 학습의 현실 문제: 비용과 효율
김태환 엔지니어는 제미나에서 일을 하던 때의 어려움으로,
모델 하나 학습에 들어가는 막대한 계산 비용을 꼽습니다.
심지어 1%만 최적화해도 금액이 크게 줄기 때문에,
학습 속도를 어떻게 빠르게 하고, 적은 칩으로 학습 효율을 올릴지가 중요한 과제였다고 말해요.
5-2. 에이전트 도입이 개발 속도를 올리지만, “환각/검증 비용”도 커진다
인터뷰 후반부에는 AI 에이전트 개발자 관점의 실무가 나옵니다.
에이전트를 쓰면 정보가 압축돼서 코딩 과정이 더 효율적이긴 한데,
LLM 기반 에이전트의 할루시네이션(환각) 문제가 생겨서,
없는 함수를 “있다”고 만들거나, 말이 안 되는 결과를 내는 경우가 있다고 해요.
그래서 2~3일을 날릴 수도 있으니,
코드가 실제로 존재하는지(함수 존재 여부)를 집체크하는 검증 루프가 필요하다고 정리합니다.
6) 채용/인재상: “API 파인튜닝”보다 “강화학습·물리/리워드 설계”가 경쟁력
6-1. 단순 사용형 엔지니어는 대체되기 쉬워진다
인터뷰에서 “API를 가져다 쓰고 파인튜닝만 하는 엔지니어”는AI로 대체될 가능성이 높다고 직설적으로 말합니다.
6-2. 경쟁력 있는 엔지니어: 강화학습 + 물리 법칙 + 리워드 설계
대신,
강화학습에서 리워드(reward)를 어떻게 잘 설계할지
물리 법칙/환경 제약을 이해해서 에이전트 아키텍처에 어떻게 녹여낼지
이런 “자기만의 전문성”이 있는 엔지니어가 더 경쟁력이 있다고 봅니다.
전하고 싶은 주요 메시지(다른 뉴스에서 잘 안 뽑히는 ‘진짜 핵심’)
이번 인터뷰의 제일 중요한 포인트는, “자율주행 회사들이 다 하고 있는 데이터 수집” 이야기가 아니라
‘자율주행을 끝내는 기준’을 시나리오 커버리지의 완전성으로 정의했다는 데 있어요.
즉,
- 현실 데이터는 필수지만, 한계가 있으니
- 월드모델로 센서 기반 학습 데이터를 생성하고
- 강화학습으로 수만~수억 단위 시나리오에서 반복 훈련하며
- “생각 가능한 모든 상황에서 완벽”이라는 기준을 향해 간다
이 흐름은 향후 자율주행뿐 아니라, 생성형 AI가 실제 산업에서 “학습 데이터의 폭발적 생산성”을 담당하는 방향을 보여주는 신호로도 읽혀요.
자율주행·AI 트렌드 관점에서 보는 연결(경제/산업 키워드 5개를 자연스럽게 반영)
- 자율주행: 현실 주행의 데이터 한계를 월드모델 시뮬레이션으로 확장하는 접근
- AI 반도체: 학습 효율/칩 비용 최적화가 핵심 과제로 반복 등장
- 생성형 AI: 월드모델이 “센서 입력 생성”을 통해 학습 재료를 만드는 역할
- 강화학습: 오픈루프의 제약을 넘어 대규모 시나리오에서 성능을 끌어올리는 엔진
- 파운데이션 모델: 리즌닝/비전-행동 연결을 통해 룰베이스 확장의 방향을 제시
< Summary >
– 웨이모는 도로 실데이터뿐 아니라 월드모델로 센서 데이터를 생성해 학습 시나리오를 대규모로 만든다.
– 목표는 “생각할 수 있는 모든 시나리오에서 트레이닝을 완벽하게” 수행하는 것으로, 그걸 자율주행의 ‘끝’으로 본다.
– 오픈루프(고정된 환경) 강화학습은 시나리오 확장에 한계가 있어, 월드모델 기반으로 이를 극복하려는 흐름이 강하다.
– 룰베이스에서 파운데이션 모델 기반으로 확장하려는 이유도, 다양하고 희귀한 상황 대비를 학습시키기 위해서다.
– 인재상은 API 파인튜닝만 하는 접근보다, 강화학습·리워드 설계·물리/환경 제약을 아키텍처에 녹이는 역량이 중요하다고 강조한다.
– AI 에이전트는 개발 효율을 높이지만 환각 검증 비용(존재 여부 집체크 등)도 커져서 실무적 검증 루프가 필수다.
[관련글…]